

AIコストを50%削減する「モデルルーティング」の新潮流:トークンマッチングがもたらす効率化の鍵
AIモデルを一つ選んで使い倒す時代は終わりを告げようとしています。プロンプトの性質に応じて最適なモデルを自動選択する「トークンマッチング」戦略が、企業のAI支出に革命を起こしています。本記事では、エンジニアが直面するコスト課題を解決し、AIの価値を最大化する最新の抽象化レイヤーについて解説します。
1. 「どのモデルが最強か」という議論の先へ
かつてDelphiユーザーがVisual Basic陣営と「どちらが優れた言語か」を激しく争ったように、現在は「コーディングにはどのAIモデルが最適か」が議論の的となっています。しかし、多くの開発チームが特定のモデルファミリーに固執する一方で、運用の現場では新たな課題が浮上していました。
2. 課題:コンテキストの肥大化と「トークンマックス」の限界
モデルとの直接対話から、GStackやSuperpowersのようなスキャフォールディングツールの活用へと進化し、私たちは「コンテキストエンジニアリング」という層を手に入れました。しかし、モデルの能力を限界まで引き出そうとする「トークンマキシマイジング(Tokenmaxxing)」に走った結果、企業には膨大なコストというツケが回ってきたのです。
3. 解決策:モデルルーティングという新たな階層
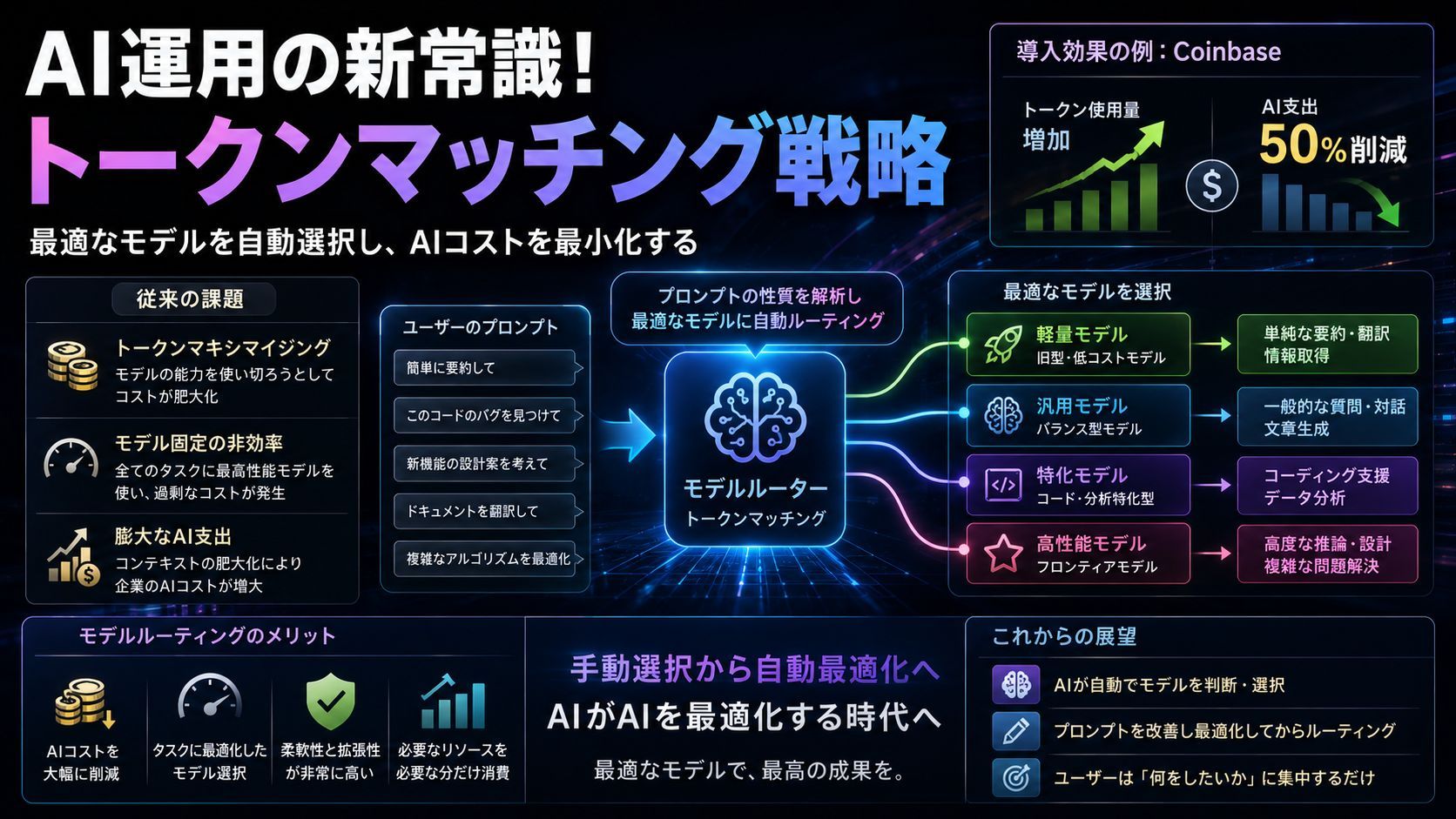
アセンブリ言語が構造化言語に、そしてフレームワークへと抽象化されてきた歴史と同様に、LLMの支出管理にも新しい抽象化レイヤーが登場しました。それが「モデルルーティング」です。
核心的な考え方: すべてのプロンプトが、最高峰のモデル(フロンティアモデル)による深い思考を必要としているわけではありません。
- 単純なリクエスト: 低コストな旧型モデルや軽量モデルへ
- 高度なコードレビュー: 特定のタスクに特化した高性能モデルへ
4. 運用の要点と導入効果
モデルルーターを導入することで、コストを流動的に管理できます。例えば、暗号資産取引所のCoinbaseは、トークンの使用量が増加しているにもかかわらず、AI支出を50%削減することに成功しました。
| 項目 | 従来の方式 (固定選択) | モデルルーティング |
|---|---|---|
| コスト | 常に最高単価 | タスクに応じて最適化 |
| 柔軟性 | 低い | 非常に高い |
| 効率 | 過剰スペックになりがち | 必要なリソースのみ消費 |
現在、オープンソースの「Claude Code Router」のように、プロンプトの要求に応じてモデルを振り分けるツールも登場しています。
5. 学びとこれからの展望:トークンマッチングの時代へ
今後は、人間が手動でモデルを選ぶのではなく、AI自身が「どのモデルが最適か」を判断し、さらにはユーザーのプロンプトを改善(前処理)してからルーティングする世界が標準になるでしょう。
私たちは特定のLLMベンダーの仕様に合わせてプロンプトを微調整する作業から解放されます。これからは「何をしたいか」を明確にすることだけに集中すれば、背後のルーターとプロセッサが、最もコスト効率の良い方法で答えを導き出してくれるはずです。