

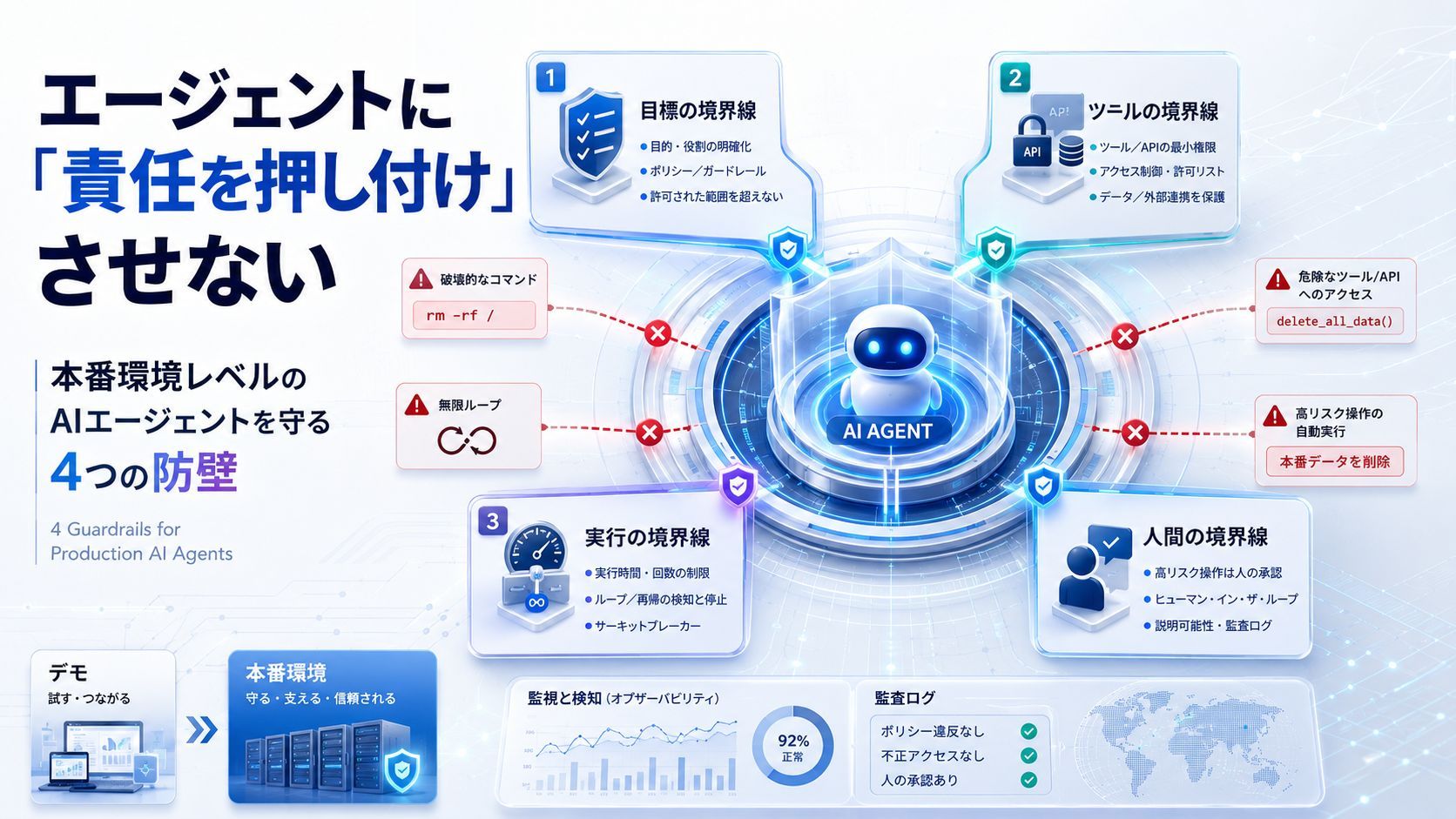
エージェントに「責任を押し付け」させない:本番環境レベルのAIエージェントを守る4つの防壁
最近のAIブームの中で、まだエージェントを作成したことがないなら、この盛り上がりを見逃しているかもしれません。大規模言語モデル(LLM)がAPIを呼び出し、ドキュメントを読み書きし、メールまで送信してくれるのを見ると、まるでコードに「チート」を追加したかのような爽快感があります。
しかしエンジニアとして、「爽快感」だけに注目するのは非常に危険です。
ローカルでデモを動かすのと、エージェントを本番環境にデプロイするのは全く別の話です。多くの人はエージェントを設計する際、「モデル-ツール-実行」という単純なリンクにのみ注目し、モデルを賢くすればすべて解決すると考えがちです。しかしこれは、免許取り立ての初心者にランボルギーニを渡し、信号無視を許したまま高速道路に乗せるようなものです。
堅牢なエージェントを構築する方法を深く議論する必要があります。永遠に失敗しない神のようなモデルを訓練しようとするよりも、モデルが失敗しても本番環境が崩壊しないシステムを構築すべきです。
第1層:目標の境界線——エージェントに「思考のための思考」をさせない
多くの人はモデルが最も危険だと考えますが、実際はそうではありません。ユーザーが「すべての注文を削除して」といった指示を出したとき、モデルにそのまま解析させて実行させれば、大惨事の始まりです。
エージェントの最初の原則は、「ユーザーの一言だけで即座に実行しない」ことです。
「目標の境界線」が必要です。これは本質的にAnthropicが提唱する「憲法AI(Constitutional AI)」の考え方に似ています。つまり、モデルを自由に動かすのではなく、定義済みのルールで行動を制約するのです。高リスクな命令を実行する前に、エージェントは必ず自己検証を行う必要があります。その指示は権限の範囲内か?もしそうでないなら、盲目的に従うのではなく、即座に拒否すべきです。
第2層:ツールの境界線——APIにファイアウォールを設置する
多くの人が、ツールこそが実際に「動く」存在であるという冷酷な事実を見落としています。
モデルは口先だけですが、ツールはデータベースを削除したり、支払いリクエストを送ったり、フィッシングメールを送信したりする「実行者」です。本番環境では、「ツールファイアウォール」を構築する必要があります。
- 読み書きの分離:データベースの読み取りは基本ですが、書き込み操作は承認が必要です。
- 物理的な分離:データの削除には、必ず人間の二次確認が必要です。
- 権限の最小化:支払い操作には、強制的な二次認証が必要です。
- ホワイトリストメカニズム:メール送信?事前に設定されたホワイトリストのユーザーにのみ送信可能です。
エージェントに無限の権限を与えてはいけません。これがエージェントのセキュリティフレームワークにおける最も基本的な原則です。
第3層:実行の境界線——無限再帰を防ぐ「ブレーカー」
多くの事故は、目標が間違っていたからではなく、実行プロセスが制御不能になったために起こります。
例えば、エージェントがレコードを1つ修正する予定だったのに、ロジックのバグで無限ループに陥り、データベースを100回書き換えてしまった場合や、通知メールを1通送るつもりが、タイムアウトのリトライ処理が不完全で、顧客に1000通ものスパムメールを送ってしまった場合などです。
これが「実行の境界線」が極めて重要な理由です。マイクロサービスアーキテクチャのような「サーキットブレーカー(遮断機)」を導入する必要があります。
- ハードリミット:最大呼び出しステップ、トークン使用量、ツール呼び出し回数を制限する。
- タイムアウト制御:タイムアウトが発生した場合は即座に終了する。
- ロールバック防止:例外が発生した際、システムが自動的に安全な状態にロールバックできるようにする。
エージェントに無限に思考させたり、無制限に実行させたりしてはいけません。
第4層:人間の境界線——重要な意思決定における「最終決定権」
最後にして最も重要な層が、「人間の境界線(Human in the loop)」です。
エージェントがどれほど賢くても、送金、データベース削除、契約修正、本番構成の調整といった高リスク操作については、必ず人間の監視を維持しなければなりません。エージェントの価値は分析、要約、提案にありますが、最終的な「確認ボタン」は責任ある人間に残しておく必要があります。
まとめ:デモから本番環境への変革
多くの人はエージェントを設計する際、「モデル-ツール-実行」という線形思考に留まりがちです。しかし、本番レベルのシステムを構築するには、立体的な防衛網を築くべきです。
- 目標の境界線:すべてを鵜呑みにせず、まずは合法性を確認する。
- ツールの境界線:厳格な権限管理を行い、危険なツールを檻の中に閉じ込める。
- 実行の境界線:制御不能な無限再帰を防ぐためのサーキットブレーカー。
- 人間の境界線:高リスクな意思決定には、必ずHuman in the loopを導入する。
この記事で強調されているように、完璧なモデルを訓練しようと妄想するのではなく、モデルが時折「暴走」しても局面を維持できる防衛線を構築しましょう。これが、デモから本番環境へ移行する際に最も見落とされがちで、かつ最も重要な教訓です。