

Close sidebar
ChatGPT 4
User
You
GCPのデータベースについて勉強しています。 dataflowのクラスタにおけるホットスポットの発生とは何ですか?
ChatGPT
ChatGPT
Momoさん、GCP(Google Cloud Platform)におけるDataflowのクラスタにおけるホットスポットについてのご質問ですね。理解いたしました。
Dataflowは、大量のデータを処理するためのフルマネージドなサービスで、Apache BeamのSDKを使用してデータ処理のパイプラインを作成し、実行します。ホットスポットの発生は、データフローの中で特定のノードやリソースに異常な負荷が集中する状態を指します。この現象は、データの分散が不均一である場合にしばしば見られます。
具体的には、次のような状況が考えられます:
キーの分布の偏り: データが特定のキーに偏っている場合、そのキーを処理するノードに高い負荷がかかります。例えば、ログデータの処理で特定のユーザーIDが多くのデータを生成している場合などです。
不均衡な処理時間: 異なるデータ要素が処理にかかる時間が大きく異なる場合、一部のノードが他よりも長時間処理を行う必要があり、これがホットスポットを引き起こす可能性があります。
この問題に対処するためには、データの分散を改善するためにパイプラインの設計を見直すことが一般的です。たとえば、キーの選択を変更する、データの前処理を行う、あるいは負荷が高い処理をより多くのワーカーで分散させるなどの方法があります。
Momoさんがデータフローの設計においてこのような問題に直面した場合、これらの観点から対処法を考えると良いでしょう。また、こうした問題への理解を深めることは、データ処理のスキルを磨く上でも非常に有意義です。
User
You
できれば簡潔に教えて欲しいです。
ChatGPT
ChatGPT
了解しました、Momoさん。Dataflowのクラスタにおけるホットスポットとは、データ処理中に特定のノードやリソースに過度な負荷が集中する状態のことです。これは主に、データの偏りや処理時間の不均衡によって発生します。この問題を解決するためには、データの分散を改善するための設計変更が必要です。
User
You
キーの分散の偏りとはなんですか?簡潔に教えてください
ChatGPT
ChatGPT
キーの分散の偏りとは、データセット内で一部のキー(例:IDや属性など)が他のキーに比べて過剰に多くのデータを持つ状態を指します。これにより、そのキーを処理するノードに負荷が集中し、パフォーマンスの低下や処理の遅延が発生する可能性があります。
User
You
それはRowKey戦略と呼ばれるものですか?
ChatGPT
ChatGPT
RowKey戦略とは、データベースやデータ処理システムにおいて、行のキー(RowKey)をどのように設計するかという戦略を指します。これは、特に分散データベースやビッグデータ処理システムにおいて重要です。
キーの分散の偏りを防ぐためのRowKey戦略には、以下のような方法があります:
キーの均等分散: キーがデータノード間で均等に分散されるように設計します。これにより、どのノードもほぼ同じ量のデータを処理することになります。
ハッシュ値の使用: キーをハッシュ関数に通して、分散を均一にします。これにより、データの集中を避けることができます。
複合キーの利用: 複数の属性を組み合わせてキーを作成することで、分散を改善します。
これらの戦略は、データのホットスポットを防ぎ、システム全体の負荷を均等に分散させるのに役立ちます。Momoさんがデータベースやデータフローを設計する際には、これらの戦略を考慮すると良いでしょう。
User
You
キーをアルファベットに均等になるようにするのも均等分散の戦略ですか?
ChatGPT
ChatGPT
はい、Momoさん。キーをアルファベット順に均等に分散させることも、均等分散の戦略の一つです。この方法は、キーのアルファベット順によってデータが均等に分布するように設計することを意味します。
例えば、顧客の姓に基づいてデータを分散させる場合、姓が"A"から始まる顧客のデータ、"B"から始まる顧客のデータ、というように均等に分散させることができます。これにより、データの偏りを減らし、各ノードへの負荷を均等にすることが可能です。
ただし、この方法はデータの実際の分布に依存します。たとえば、特定のアルファベットで始まるキーが非常に多い場合は、それでも偏りが生じる可能性があります。そのため、実際のデータの特性をよく理解し、適切な戦略を選択することが重要です。
User
You
ここまでの会話を、簡潔にまとめてください
ChatGPT
ChatGPT
もちろんです、Momoさん。ここまでの会話の要点は以下の通りです:
Dataflowのホットスポット: Dataflowのクラスタにおけるホットスポットは、特定のノードやリソースに過度の負荷が集中する状態です。これは、データの分散が不均一である場合に発生します。
キーの分散の偏り: これは、データセット内で一部のキーが過剰に多くのデータを持つことを意味します。これにより、パフォーマンスの低下や処理の遅延が起こる可能性があります。
RowKey戦略: これは、分散データベースやビッグデータ処理システムにおいて、行のキーをどのように設計するかという戦略です。均等なデータ分散を実現するためにキーの設計を工夫します。
アルファベットによる均等分散: キーをアルファベット順に均等に分散させることも均等分散の一つの方法ですが、実際のデータの特性によって効果が変わります。
このように、データの均等分散はパフォーマンスの向上とホットスポットの防止に重要な要素です。
User
You
今までの会話を整理したいです。日本語でマインドマップの形で下記のステップでまとめてください。 1.まず「マインドマップ:」という文字列を先頭に入れてください。 2.そして改行を入れてください。 3.マインドマップの内容を作ってください。必ずmarkdownの記述方式で出力してください。
ChatGPT
ChatGPT
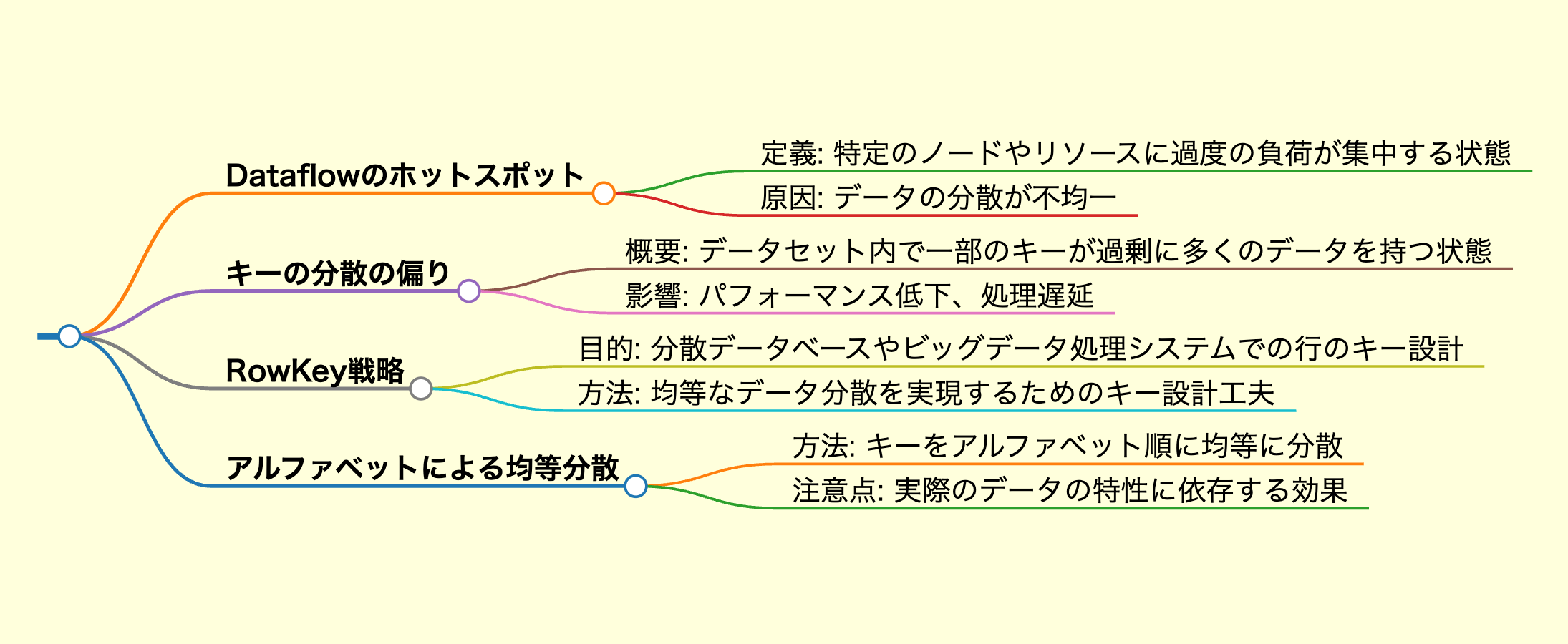
マインドマップ:
markdownCopy code
- **Dataflowのホットスポット**
- 定義: 特定のノードやリソースに過度の負荷が集中する状態
- 原因: データの分散が不均一
- **キーの分散の偏り**
- 概要: データセット内で一部のキーが過剰に多くのデータを持つ状態
- 影響: パフォーマンス低下、処理遅延
- **RowKey戦略**
- 目的: 分散データベースやビッグデータ処理システムでの行のキー設計
- 方法: 均等なデータ分散を実現するためのキー設計工夫
- **アルファベットによる均等分散**
- 方法: キーをアルファベット順に均等に分散
- 注意点: 実際のデータの特性に依存する効果
User
You
今までの会話をブログに作りたい。マインドマップ作成の内容を除いて、 タイトルと集約文、そしてSEO対応のため、キーワードを「,」区切りでまとめてください。出力文のフォーマットは「タイトル:」「集約文:」「キーワード:」の形でお願いいたします。「タイトル:」「集約文:」「キーワード:」は改行2回で区切りしてください。そして「タイトル」「集約文」「キーワード」以外の説明がいりません。そして日本語で出力してください。
ChatGPT
ChatGPT
タイトル: GCP Dataflowのホットスポットとキー分散戦略
集約文: この記事では、Google Cloud Platform(GCP)のDataflowにおけるホットスポットの原因と対策について説明します。特に、キーの分散の偏りやRowKey戦略、アルファベットによる均等分散など、データベースやデータ処理システムにおいて重要なキー設計の工夫に焦点を当てています。
キーワード: GCP, Dataflow, ホットスポット, キーの分散, RowKey戦略, データベース, ビッグデータ, アルファベット分散, データ処理
ChatGPT can make mistakes. Consider checking important information.
?